Attribute Library: Designing the core of a PIM
Summary:
Building a product data platform is easy until you need to describe the product.
Prodify is a PIM built for building product manufacturers, companies whose products have dozens of technical attributes that need to be accurate, consistent, and publishable across multiple channels. Early in the platform's development, attributes could be created freely, per context, with no shared definition. The result was predictable: "Fire Rating," "fire rating," and "FireRating" coexisting as three separate things that meant the same thing.
This case study is about fixing that, not with a policy, but with architecture.
I designed a centralized attribute library: a single place where every attribute is defined once, typed, configured, and then explicitly assigned to the product families that need it. The work spanned product architecture decisions (implicit vs. explicit assignment models), governance UX (how admins create, manage, and audit attributes at scale), and the downstream consequences, import flows, variant editing, channel publishing, and integration mapping all touched this decision.
The hardest part wasn't designing the library. It was making a high-control system feel lightweight enough that a manufacturer managing 300 SKUs wouldn't dread opening it.
💼 Role:
Sole Product Designer with PM responsibilities
⏱️ Timeline:
1 Quarter
💻 Platform:
Web
🎯Objective:
Establish a centralized attribute schema that enables consistent, governed product data across families and integrations
Discovery: Are we building Prodify's Integration on a strong foundation or on sand?
I wasn't handed this problem. I found it while researching how Prodify could connect to Integration channels, specifically how other PIMs handle attribute mapping when integrating with platforms like Shopify or Amazon.
I spent a full day going deep on Plytix (competitor PIM) watching their product walkthroughs on YouTube, understanding how they govern product data end to end. The moment that stopped me was their integration mapping step: attributes could be mapped, toggled off, translated, or converted per channel.
That's when I realized, for that to work, every attribute has to be centrally defined and typed. You can't map what doesn't have a schema.
I dug further. Akeneo, Salsify, Pimcore, every mature PIM treats attributes as a governed, centralized library. Not per-product settings. And every one of them had a readiness engine built on top of attribute completion. (Something that I was already thinking about as another dependancy to PIM syndication).
I recorded a video of my findings and shared it with our data analyst. Her response confirmed the direction: a centralized attribute library is the scalable way to build a PIM. Without it, every downstream system: integrations, publishing pipelines, readiness scoring, would be building on sand.
The Problem with the old structure
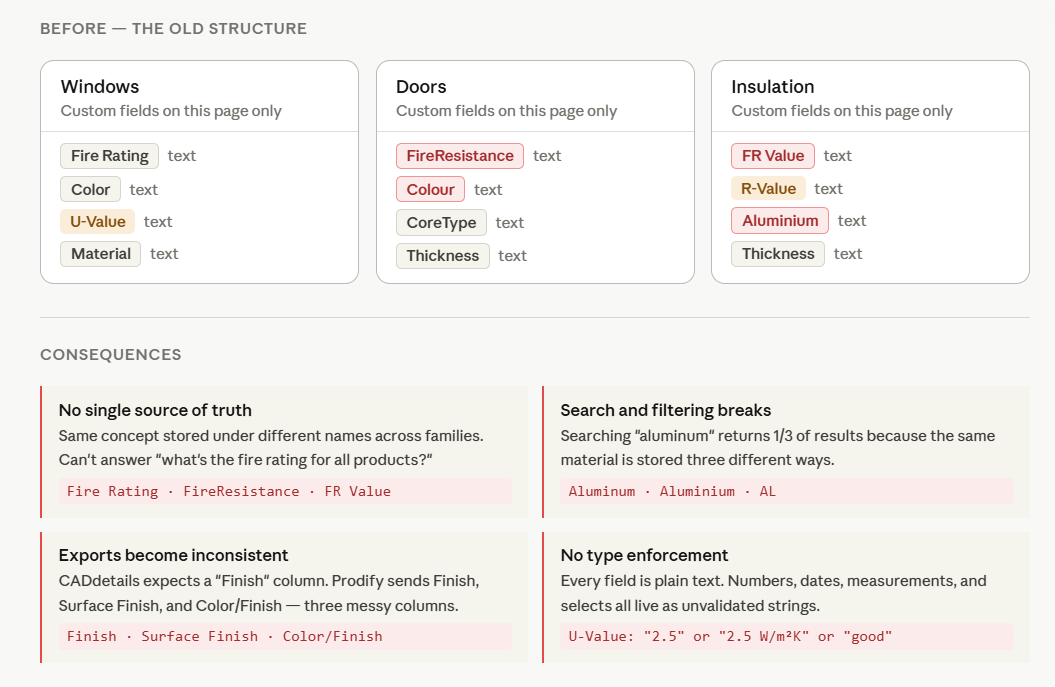
Dependencies and architecture
Before I opened Figma, I mapped everything that would sit on top of the attribute library. This wasn't just a design project , it was a foundational infrastructure decision. Getting it wrong would mean rebuilding half the platform later.
I created an Integration Breakdown diagram showing the full stack: three syndication channels (CADdetails, Design Hub, Third Party) sitting above a layer of syndication foundations:
Completeness/Readiness, Attribute Eligibility, Attribute Mapping, Category Mapping, Taxonomy Mapping, Products & Collections, Assets, Related Products, and Channel Log. Everything upstream depended on everything below it being stable and typed.
The insight from this mapping was that the attribute library wasn't one feature , it was the load-bearing wall for six others.

Requirements
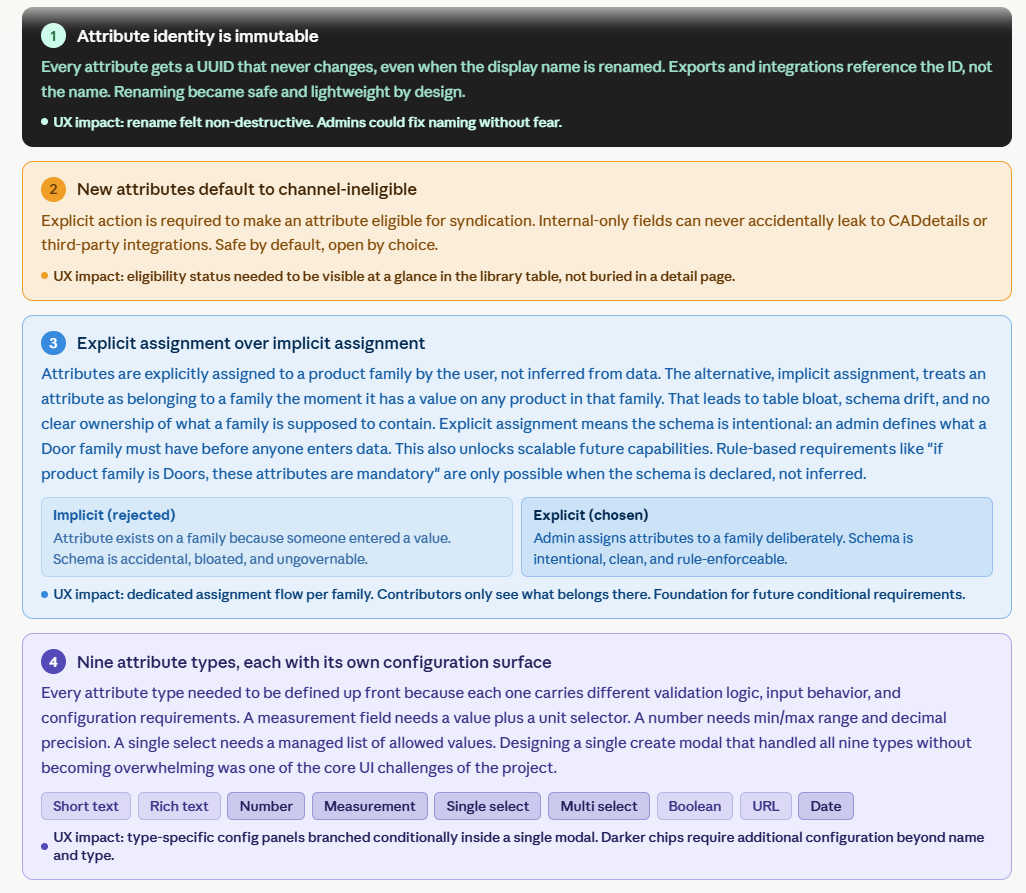

Thinking about this structure of Attributes, made it clear to me that our existing Importer, is not compatible with the new schema. The importer is the primary way attributes enter the system during onboarding or large catalogues are updated by enterprise customers.
The old importer had no schema to map to, it created attributes on the fly from whatever columns appeared in the CSV. The new importer needed the centralized library to exist first, so it could map incoming columns to defined, typed attributes rather than creating new ones silently. You can't build a centralized library and then have an importer that bypasses it entirely. So the importer became its own project, sequenced directly after this one.

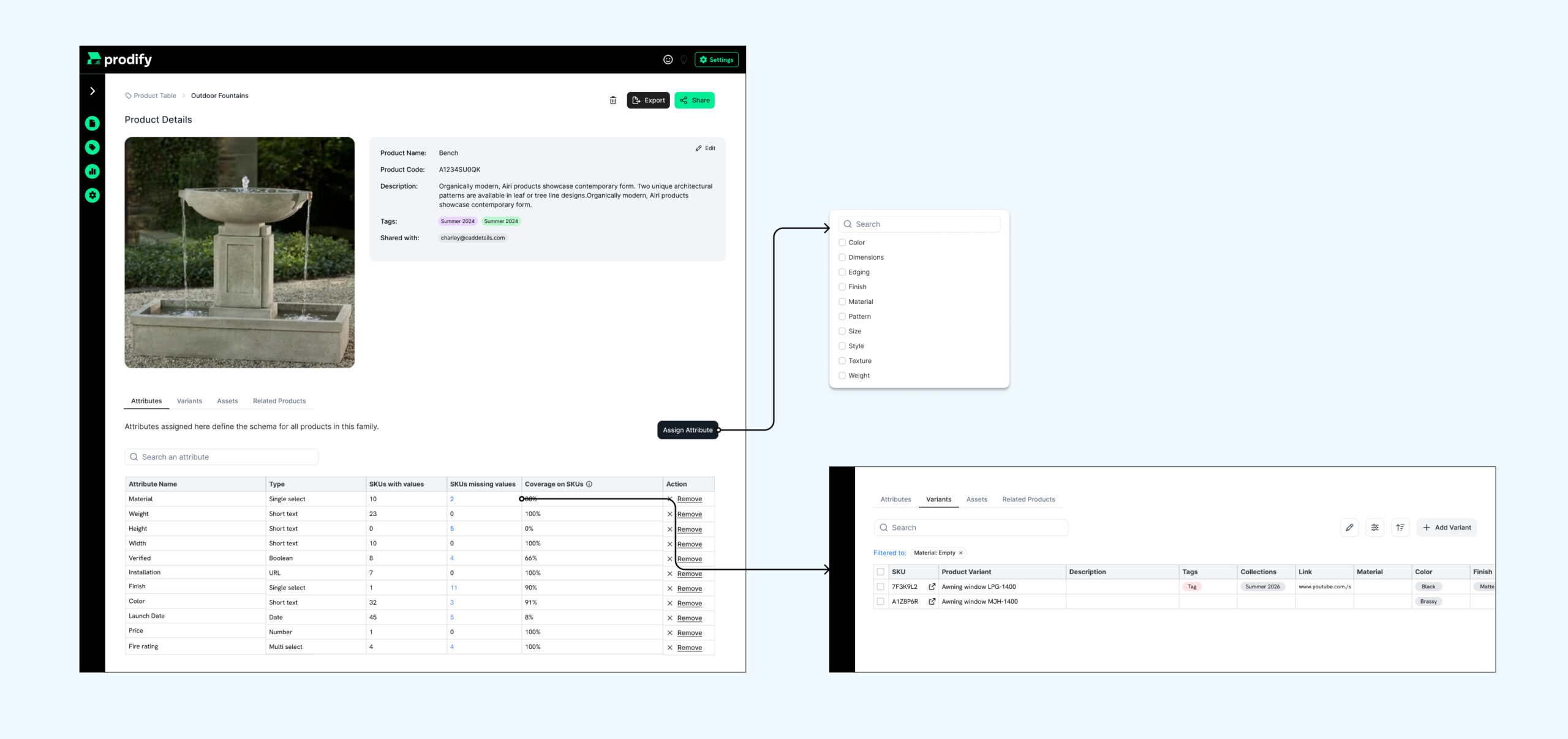
High Fidelity Designs
Below is the flow of creating the attributes in a centralized library. This includes defining attribute data type and for single select or multi-select data types, defining acceptable options to avoid drifting when editing. I went a step further in UX to make sure the centralized attribute page, is an overlooking data management hub that gives the admin user visibility into their attribute coverage across product families and individual SKUs. This has a significant UX impact in bridging the gap between creation and management of data and creeating a seamless workflow.
Click here for protoype.
Assigning an attribute to the Product Family and tracking coverage.
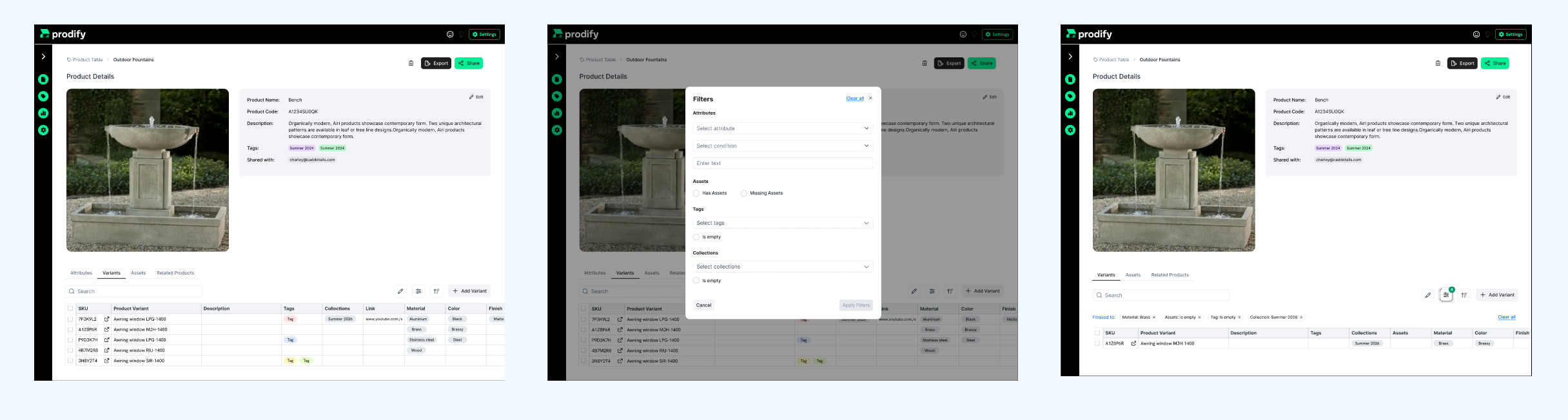
Attributes can only have values on the SKU (product) level. It's imperative for the user to be able to find, edit and manage product data effectively across hundreds of SKUs. So building a strong filtering logic was my next important UX design task.
Validation plan prepped for iteration
Usability: Can admins navigate the assignment model without training?
The explicit assignment model adds a step that didn't exist before. The risk is that new admins don't understand why they need to assign attributes to a family before they appear on products. The validation question is: can a new PIM admin set up a product family schema end to end without guidance? Success looks like zero support tickets asking "why can't I see my attribute on my product."
Comprehension: Does the Locations section communicate fill rate clearly?
The Locations section is a coverage tracker, not an assignment interface. That distinction is subtle. The validation question is: do users read it as observational data or do they try to use it to manage assignments? If they try to assign from the Locations section, the design has failed to communicate intent. Success looks like active interaction of users with the Locations section to manage attribute values and increase data coverage.
Data quality: Did duplicate attributes decrease after launch?
The entire project was motivated by schema chaos. The most meaningful design validation is whether the system actually reduced it. Baseline the number of near-duplicate attribute names before launch, then measure again 60 days after. A meaningful reduction confirms the governance model is working as designed.
Importer: Does field mapping reduce manual correction?
One of the old importer's biggest failures was creating attributes silently. The validation question for the redesigned importer is: what percentage of imports complete without requiring manual attribute correction after the fact? A high clean-import rate means the mapping UI is working.
✏️💭 The biggest lesson from this project for me was, when you're designing governance systems, the structure has to feel like help, not compliance.
Selected Works

Employee approval of punchesProduct Design case study - Mobile & Web | end to end
Building the core PIM foundation: Product Attribute LibraryProduct Design case study - Web | Prodify